
DEEP FOREST
深度随机森林
任星彰 xzhren@pku.edu.cn

周志华:深度随机森林
◦ https://arxiv.org/abs/1702.08835
◦ 2017 Feb

深度学习的缺陷
◦ 深度学习要求大规模数据集,事实上,标签数据却很缺少而且质量不高
◦ 深度学习很难懂,需要很强大的计算资源
◦ 深度学习有太多超参数,模型效果很强依赖于超参数的调整
◦ 深度学习有无限的结构组合,使得深度学习更像一个艺术,而不是科学/工程

深度随机森林
◦ gcForest:multi-Grained Cascade Forest 多粒度级联随机森林
◦ 一个新颖的决策树融合算法
◦ gcForest更容易训练:相比于深度神经网络需要超参数的调整
◦ gcForest可以根据可获得的计算资源控制训练消耗
◦ gcForest可以并行计算
◦ gcForest在小规模的训练集上效果也很好:相比于深度神经网络需要大规模训练集
◦ 在表征学习方面,深度学习的优势是因为其capacity很大,赋予简单模型,也可以达到相似的效果

目录
◦ gcForest方法论
◦ 级联森林结构
◦ 多粒度扫描
◦ 总体架构和超参数
◦ 实验验证
◦ 实验配置
◦ 实验结果\多粒度的作用\实验运行时间
◦ 后续
◦ 更多的实验
◦ 未来工作
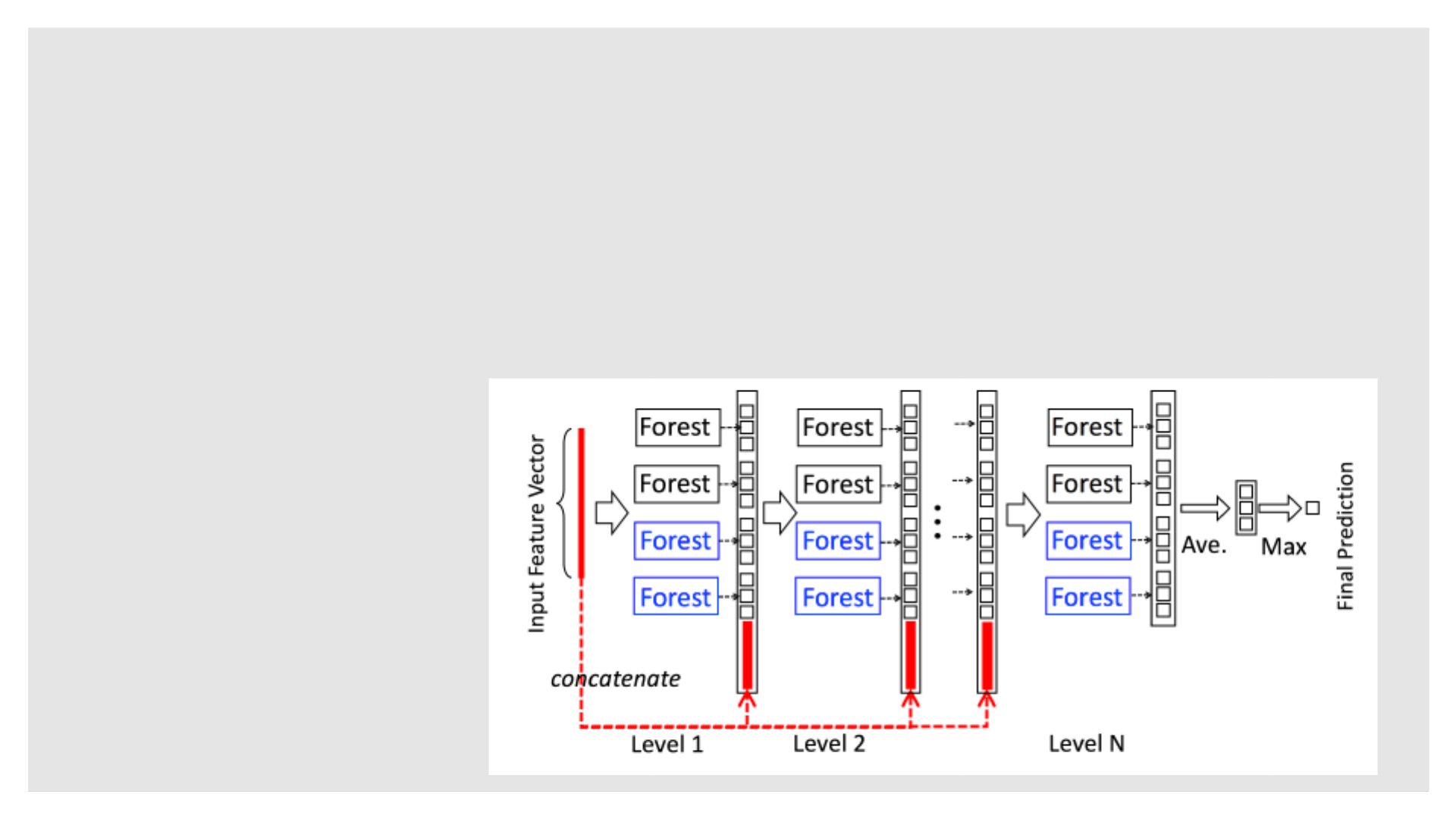
级联森林结构
◦ 每一层都是一个决策树森林的融合
◦ 使用不同类型的森林,来体现差异性(diversity)
◦ 每个森林包含的决策树数目是一个超参数
◦ 黑:随机森林
◦ 蓝:完全随机森林
◦ 假定:
◦ class_num = 3
gcForest方法论
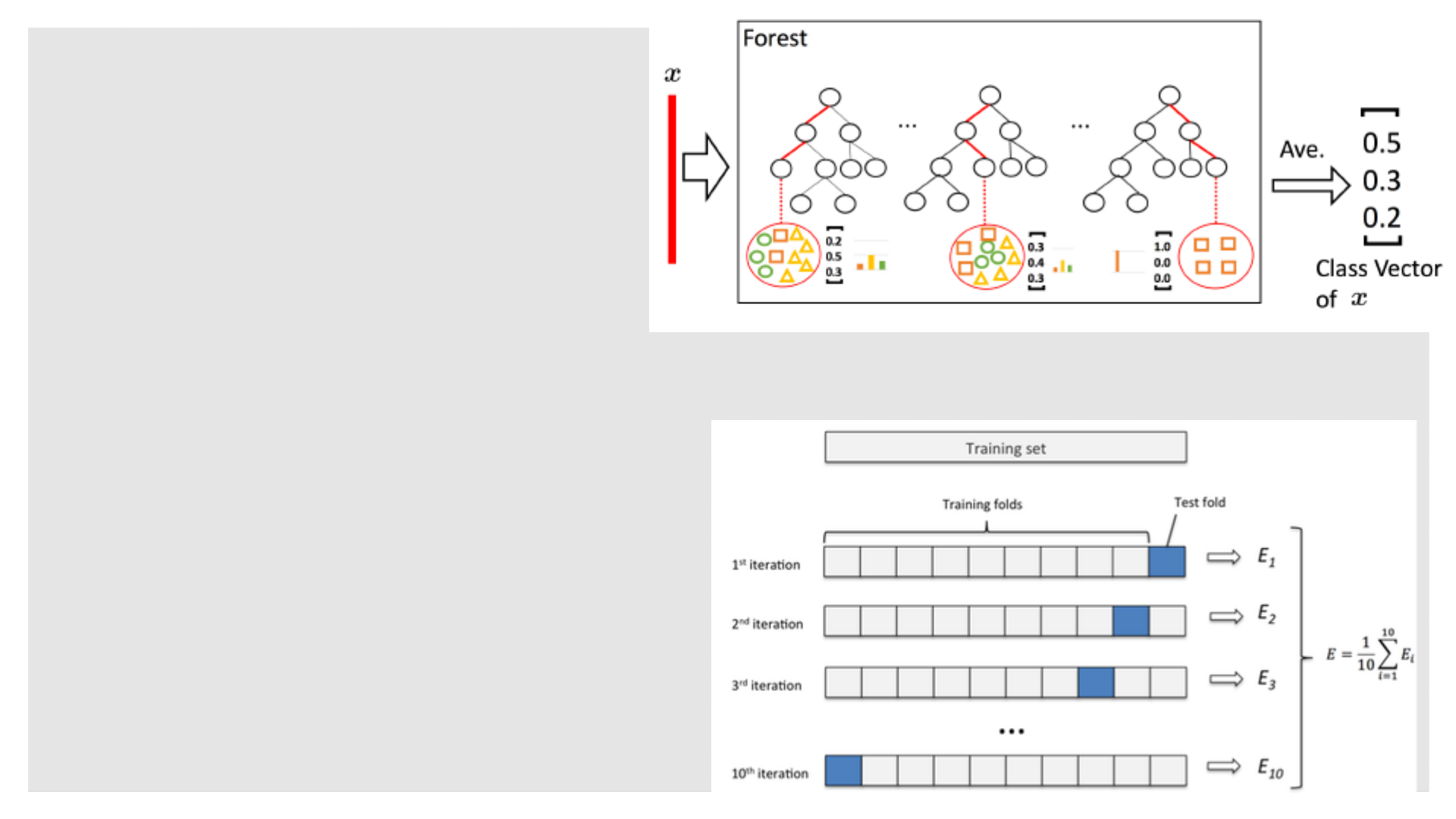
级联森林结构
◦ 类向量的生成
◦ 对于一个实例,每个树都会生成一个类分布向量,通过计算叶子节点中不同类别的比例
◦ 每个森林最终的类向量是所有树生成类分布向量的平均
◦ 最终的类标签是类向量的最大值所在的类
◦ 避免过拟合
◦ 利用k-fold CV
◦ 每个数据被利用T-1次,T为迭代次数
gcForest方法论

多粒度的扫描
◦ 借鉴深度学习的特征关系处理:
◦ CNN对图像空间关系的处理
◦ RNN对序列数据时序关系的处理
◦ 从原始数据中窗口提取的特征向量
被视为相同label的实例
◦ 连接导致特征维度过高:
◦ 利用特征采样技术
◦ 原始数据400维
◦ 窗口100维
◦ 分类数3
gcForest方法论
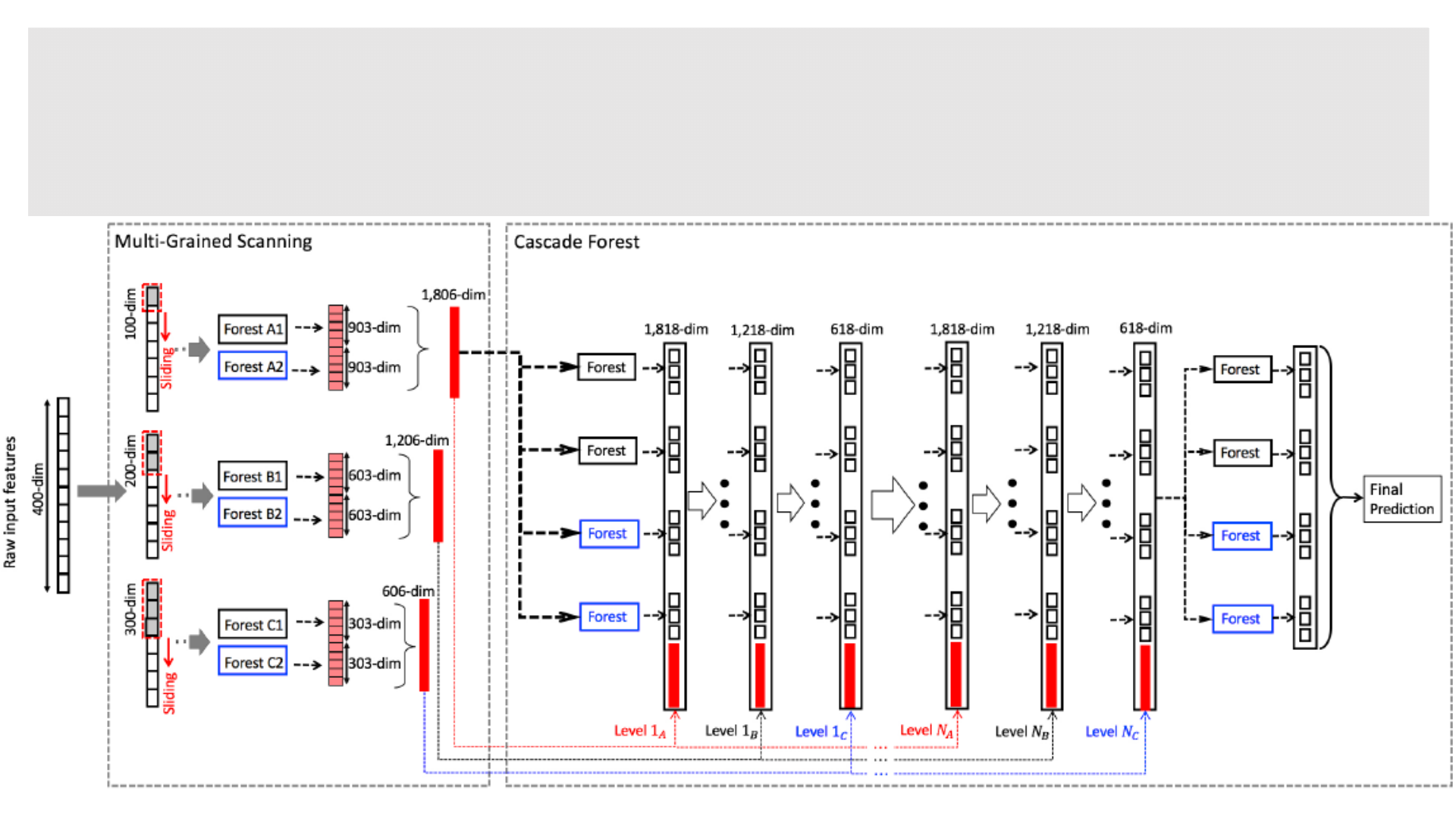
总体架构图
◦ 分类数目:3,原始特征数目:400,3个不同size的窗口
gcForest方法论

超参数
◦ ? 代表默认值未知,或者不同任务默认值不一样
◦ 加粗的超参数表示对模型有比较大的影响
gcForest方法论

实验配置
◦ 配置
◦ 随机森林使用相同的结构
◦ 每层包含4个完全随机森林和4个随机森林,每个森林包含500个树
◦ 3-fold交叉验证用来进行类向量生成
◦ 级联的层数自动终止
◦ 将数据集分为growing set(80%)和estimating set(20%)
◦ growing set用来训练级联森林
◦ estimating set用来评估模型性能
◦ 当增加新的层数不会提供模型性能的时候,
◦ 对于多粒度级联网络,使用三个大小的窗口 [d/16, d/8, d/4](d是原始特征数)
◦ 深度神经网络,由于对于不同的任务模型不能相同,因此没有默认,进行实验,选最好的对比
实验验证
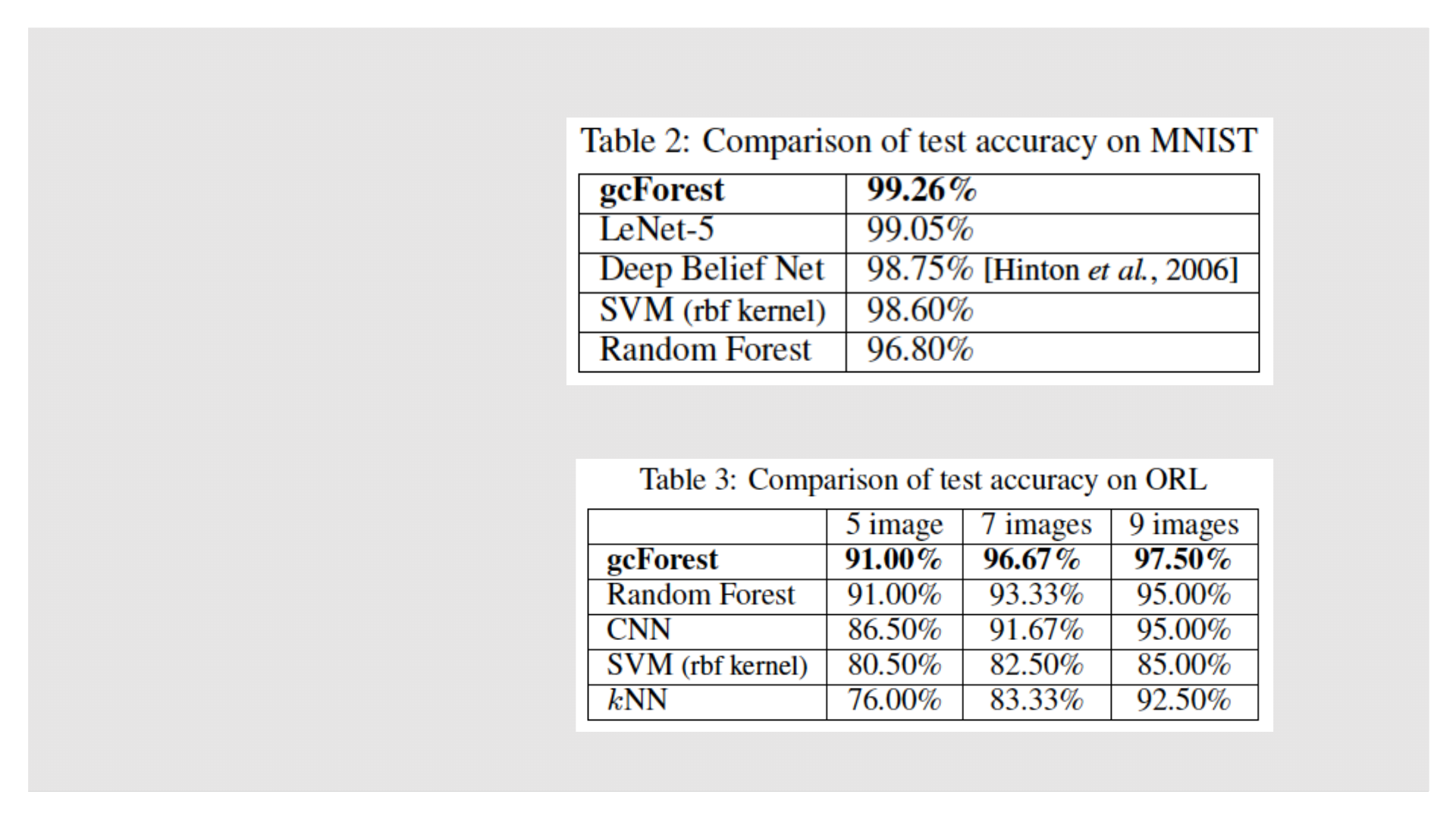
实验结果
◦ 图像分类:MNIST
◦ 人脸识别:ORL
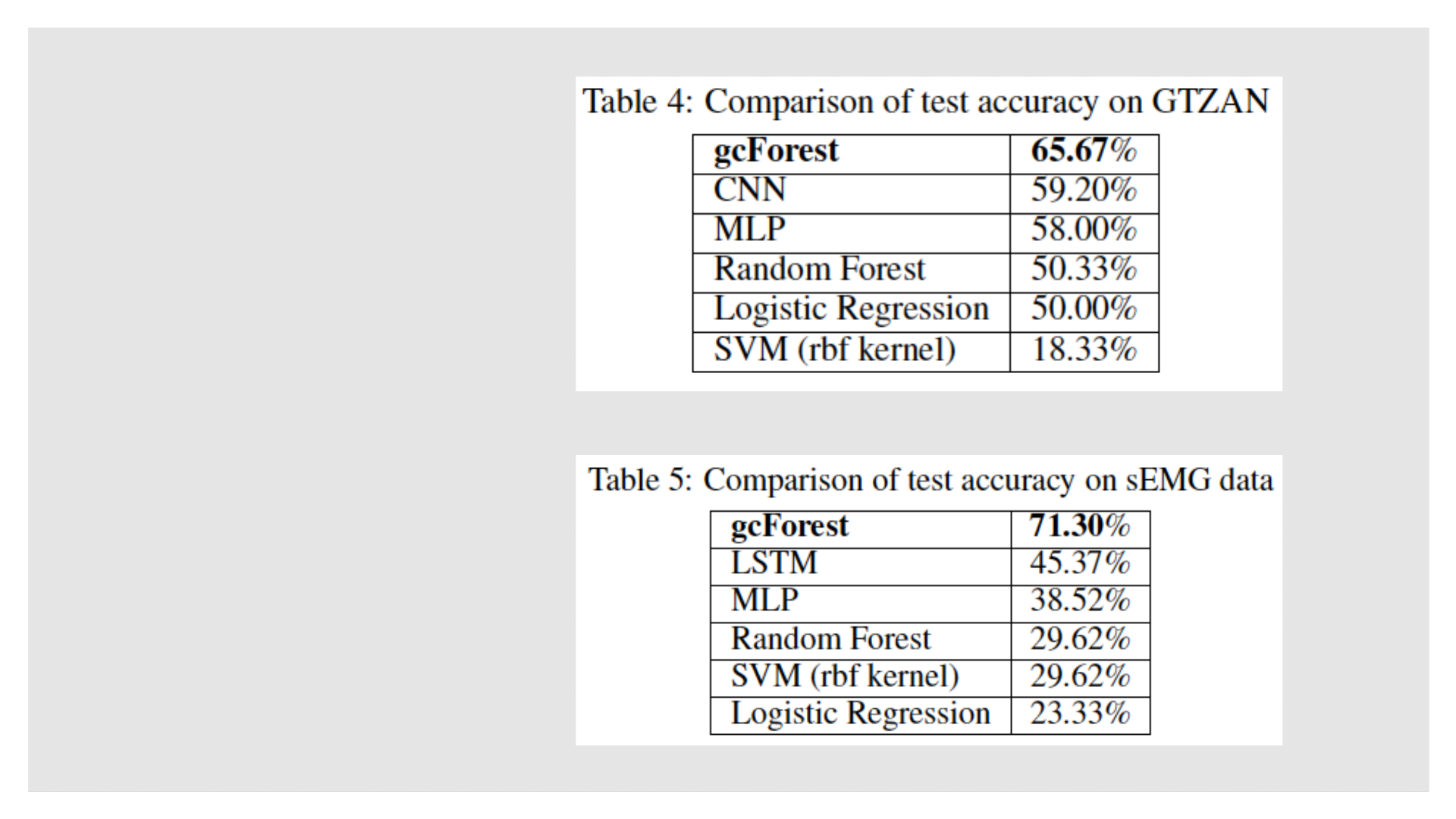
◦ 音乐分类:GTZAN(MFCC特征)
◦ 手影识别:sEMG
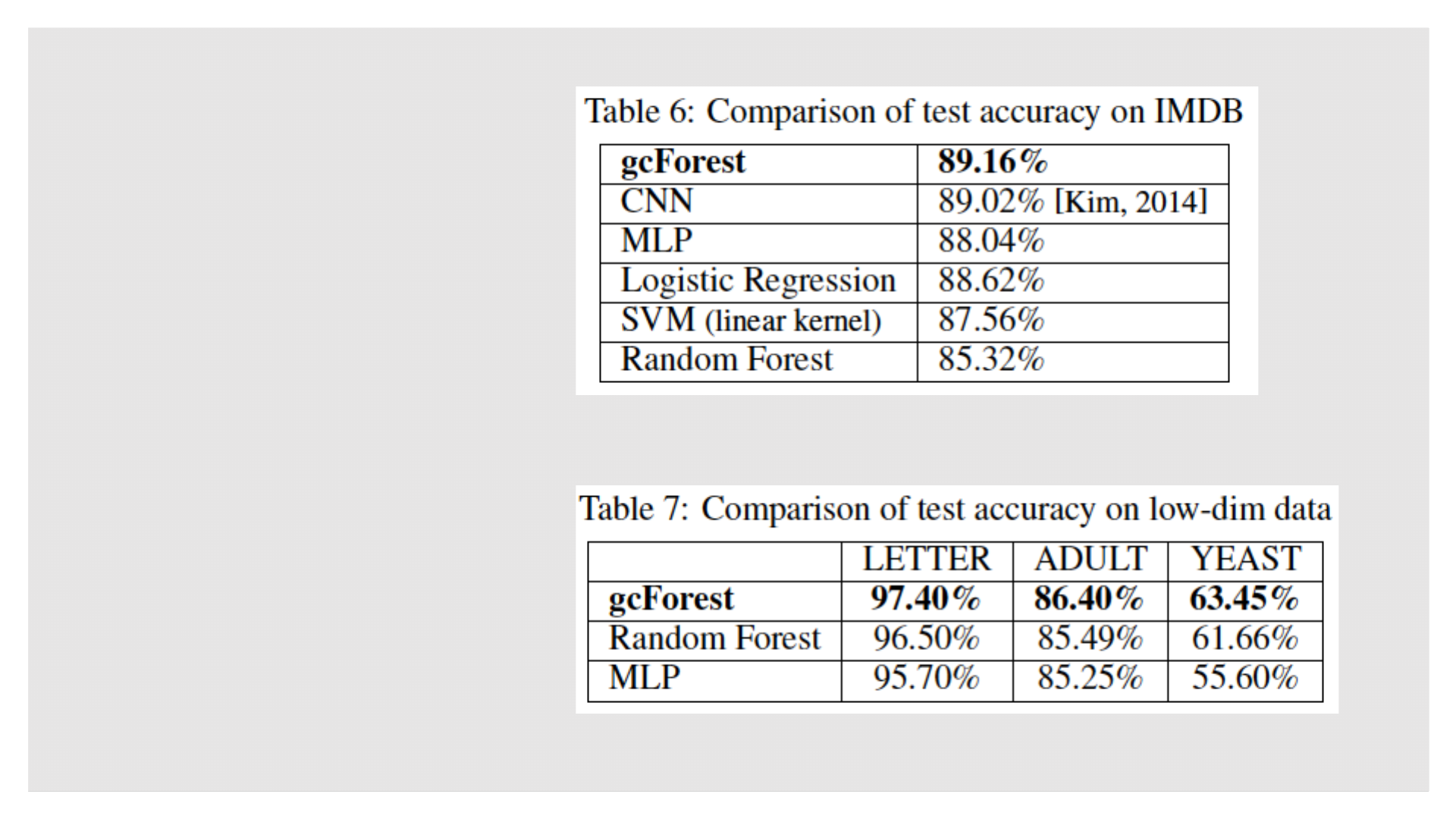
◦ 情感分类:IMDB
◦ 低维数据:LETTER(UCI)
实验验证
实验结果
◦ 图像分类:MNIST
◦ 人脸识别:ORL
◦ 音乐分类:GTZAN(MFCC特征)
◦ 手影识别:sEMG
◦ 情感分类:IMDB
◦ 低维数据:LETTER(UCI)
实验验证
实验结果
◦ 图像分类:MNIST
◦ 人脸识别:ORL
◦ 音乐分类:GTZAN(MFCC特征)
◦ 手影识别:sEMG
◦ 情感分类:IMDB
◦ 低维数据:LETTER(UCI)
实验验证

实验结果
◦ 多粒度扫描的影响
实验验证

实验
◦ 运行时间
◦ 2 Intel E5 2695 v4 CPUs (18 cores)
◦ IMDB(25000样本5000特征)
◦ gcForest:267.1s/level,9 levels,40mins
◦ MLP:93s/epoch,50 epochs,77.5mins
◦ 文章指出:单纯直接对比两者的运行时间是不公平的
◦ 没有把神经网络的设计时间考虑进去
◦ gcForest没有精心设计、调参
◦ gcForest可以进行并行还有优化空间
◦ gcFoest可以通过粒度、层数来控制模型性能
实验验证

更多实验
◦ CIFAR-10 [Krizhevsky, 2009]
◦ 训练:5w张32X32的10分类图像
◦ 测试:1w张32X32的10分类图像
◦ gcForest与state-of-art的技术相比
后续

更多实验
◦ 调参实验
◦ 粒度:窗口的个数
◦ 每层的森林个数
◦ 每个森林中树的个数
后续

未来工作
◦ 特征采样
◦ 随机采样
◦ BLB
◦ 特征哈希
◦ 难分样本挖掘(hard negative mining)
◦ 二次学习策略(Zhou and Jiang, 2004)
◦ 完全随机森林
◦ 未标记数据
◦ 增强多样性
◦ 半监督学习
后续

eForest 深度自编码随机森林
◦ EncoderForest,eForest
◦ Forward Encoding 编码过程
◦ 比较直观简单,直接对应叶子节点在树中的路径
◦ 对于数据x,对于T棵树的森林F,x的编码是T长度的1维向量
◦ 其每个元素是每棵树中对应叶子节点的索引
◦ Backward Decoding 解码过程
◦ 定义了MCR,最大可计算规则,是所有关于x的树的编码的规则的最大集
◦ 其次,取MCR中每个属性的统计值(e.g. 数值类型取均值)
◦ 应用:表征学习(represent)
◦ 图像表征(MNIST、CIFAR-10)、文本表征(IMDB)
◦ 其他研讨:计算效率、Damage Tolerable(损伤容限法)、模型复用

相关论文
◦ gcForest:Zhi-Hua Zhou, Ji Feng. Deep Forest: Towards An Alternative to Deep Neural
Networks. 28 Feb 2017
◦ eForest :Ji Feng, Zhi-Hua Zhou. AutoEncoder by Forest. 26 Sep 2017
◦ 连体gcForest:Utkin L V, Ryabinin M A. A Siamese Deep Forest[J]. 2017.
◦ 利用完全随机森林解决SENC问题:Mu X, Ming K, Zhou Z H. Classification under Streaming
Emerging New Classes: A Solution using Completely-random Trees[J]. IEEE Transactions on
Knowledge & Data Engineering, 2016, PP(99):1605-1618.
◦ Memory Network:Weston J, Chopra S, Bordes A. Memory Networks[J]. Eprint Arxiv, 2014.
◦ MIML:J. Feng and Z.-H. Zhou. "DeepMIML network" In: Proceedings of the 31st AAAI
Conference on Artificial Intelligence (AAAI'17), San Francisco, CA, 2017.
◦ 完全随机森林、iForest 异常检测随机森林
◦ 邓力的论文深度学习stacking

相关实验
◦ Cifar10(50000/10000x32x32x3)没有跑完,最好成绩应该是61.78% [FG-Forest]
◦ 运行成绩47.13%,运行24小时,挂起10小时,fit一次2.3小时,数据维度:5632770,2817230,1690000
◦ MNIST(60000/10000x28x28)没有跑完,最好成绩应该是99.26% [FG-Forest]
◦ 从87.85%提升到96.78%,运行34小时,挂起>13小时,内存消耗>40G(+虚拟内存)
◦ UCI letter数据集(16000/4000x16)最好成绩97.40% [cascade-Forest]
◦ 96.25%到97.40%,历时9mins,最优层ID=2
◦ Kaggle二分类数据集(595212/892816x227)目前最好成绩0.288(nor-gini) [cascade-Forest]
◦ 不做特征工程:Xgboost最好成绩0.280,XGB+LGB Stacking 0.282,RF 0.249,GBDT 0.273
◦ cForest(e=50,d=10,n=2,Bagging) 0.257,8分钟,最优层ID=4,Local CV(0.257/0.263)
◦ cForest(e=50,d=10,n=8,Bagging) 0.259,1.25小时,最优层ID=5,Local CV(0.262/0.253)
◦ cForest(+GDBT,e=50,d=10,n=3) 0.272,运行18小时挂起5小时,最优层ID=3,Local CV(0.266/0.281)

相关实验
◦ 执行程序消耗CPU(并行)和RAM(级联),而且会无端挂起?
◦ 利用第三方数据,遇到第二三层就达到最好效果的情况,之后训练会越来越差
◦ 特征是否可以被替换,还是并列;如何做特征采样;数据采样RF已经做了
◦ 尝试加入Boost方法,可行,但是效率大大降低;可以换成XGBoost?
◦ 能否输出依据样本和路径,作为分析判断的依据
◦ 发现普遍测试集的表现优于训练集,证明RF的泛化性很优秀
◦ 单个森林的表现优于AVG的表现,如何解决,为什么?

感谢聆听
欢迎指正